Internals¶
Architecture¶
Auctus is a cloud-native application divided in multiple components (containers) which can be scaled independently.
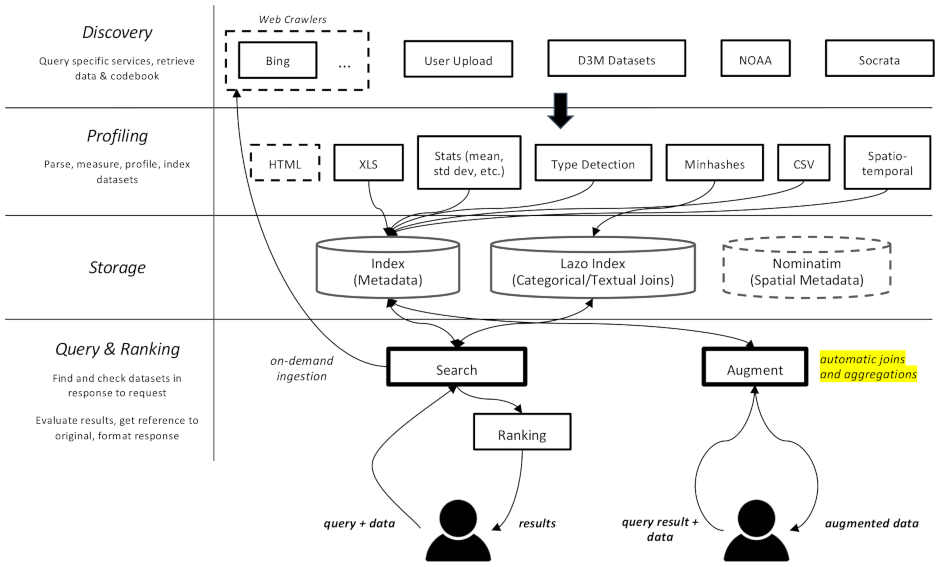
Overall architecture of Auctus¶
At the core of Auctus is an Elasticsearch cluster which stores sketches of the datasets, obtained by downloading and profiling them.
The system is design to be extensible. Plugins called “Discoverers” can be added to support additional data sources.
The different components communicate via the AMQP message-queueing protocol through a RabbitMQ server, allowing the discoverers to queue datasets to be downloaded and profiled when profilers are available, while updating waiting clients about relevant new discoveries.
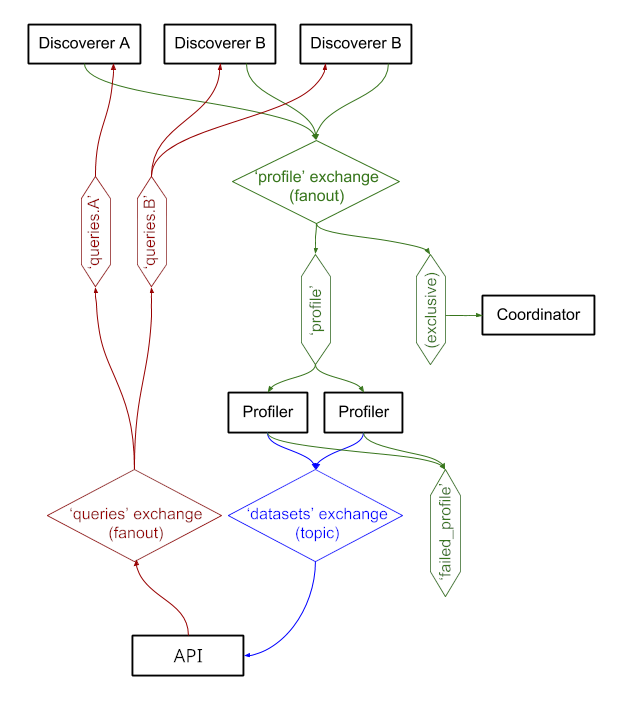
AMQP queues and exchanges used by Auctus¶
Discoverers¶
A discoverer is responsible for finding data. It runs as its own container, and can either:
announce all datasets to AMQP when they appear in the source, to be profiled in advance of user queries, or
react to user queries, use it to perform a search in the source, and announce the datasets found, on-demand.
Either way, a base Python class is provided as part of datamart_core that can easily be extended instead of re-implementing the AMQP setup.
- class datamart_core.discovery.Discoverer(identifier)¶
Base class for discoverer plugins.
- main_loop()¶
Optional entrypoint of the discoverer.
Not necessary if the discoverer is only reacting to queries.
- handle_query(query, publisher)¶
Optional hook to react to user queries and find datasets on-demand.
Not necessary if the discoverer is only discovering datasets ahead-of-time.
- publisher(materialize, metadata, dataset_id=None)¶
Callable object used to publish datasets found for that query. They will be profiled if necessary and recorded in the index, as well as considered for the results of the user’s query.
- Parameters
materialize (dict) – Materialization information for that dataset
metadata (dict) – Metadata for that dataset, that might be augmented with profiled information
dataset_id (str) – Dataset id. If unspecified, a UUID4 will be generated for it.
- record_dataset(materialize, metadata, dataset_id=None)¶
Publish a found dataset.
The dataset will be profiled if necessary and recorded in the index.
Write a file to persistent storage.
This is useful if there is no way to materialize this dataset again in the future, and you need to store it to refer to it. Materialization won’t occur for datasets that are in shared storage already.
- delete_dataset(*, full_id=None, dataset_id=None)¶
Delete a dataset that is no longer present in the source.
- class datamart_core.discovery.AsyncDiscoverer(identifier)¶
Async variant of Discoverer.
Profiling¶
The profiling is done entirely by the Profiling library. It functions as follows:
First, the data is loaded or prepared as a pandas
DataFrameIf the input is already a DataFrame, its index will be turned into a column (using
df.reset_index()) if it is not the default (sequential range starting from zero).If the input is a file name or a file object, its size in bytes is measured, then it is loaded as a CSV file. If that file is bigger than
load_max_size, a random sample of that size is loaded instead.
If
metadatawas provided, check that the number and names of columns match the data. Otherwise, start from empty column dicts.For each column…
Determine its type using simple heuristics. If there is
manual_annotationsin themetadata, we use those types.Most types are detected by matching regular expressions. If most values match, that type is assigned, and the other values are counted as unclean (the threshold is set to 2%).
Empty values are treated differently, counted as separate “missing values”
If a column is not numerical and contains a majority of values with multiple words, it gets labeled as “free text”/”natural language”
If a column is not numerical and has only a few different values, it is labeled categorical (threshold: 10% of the total non-empty values)
If most values are found to be the names of administrative areas (with datamart-geo) of the same administrative level (where 0 = country, 1 = state, … up to 5), the column type is set to administrative areas of that level.
Integer columns named “year” get recognized as a temporal column containing year numbers
This is an exception to the rule below, where only non-numerical columns get tested for datetimes.
ToDo: accept more column names
Real columns named “latitude”, “longitude”, or similar (e.g. “lat”, “long”) and that have a compatible range of values get labeled as possible latitude and longitude columns. That type will be removed if the columns can’t be paired up, see below.
Non-numerical columns get fed through a date parser. Only dates that represent a specific moment in time are accepted, no matter its resolution; for example “2020” is accepted (year precision, but a single moment) but “October 3” is not (could be any year). If most values parse cleanly (again 2% unclean threshold) the column is labeled a datetime column.
Ranges are computed from numerical data using clustering (maximum 3 distinct ranges that cover the data)
Textual values get resolved into latitude and longitude pairs using Nominatim, if available. If most values are found to be addresses, that semantic type is applied.
Textual columns that are not addresses or datetimes are run through Lazo to either add them to the index, or get a sketch of the values for use in queries
ToDo: the Lazo index gets updated at this point, so if the overall profiling fails, this can’t be rolled back
Possible latitude and longitude column are paired up based on their names, for example “pickup latitude” and “pickup longitude” will correctly form a pair because their name match after removing the keywords “latitude” and “longitude. Columns that can’t be paired up get the semantic type removed.
Spatial ranges are computed from spatial data (geo points, latitude+longitude pairs, addresses, and administrative areas)
Dataset types get computed from the column types and applied to the metadata, e.g. if the dataset has a column of real numbers it is “numerical”, if it has longitudes or administrative areas it is “spatial”, etc.
Spatial ranges are computed from the resolved locations using clustering (maximum 3 distinct bounding boxes that cover the data)
The profile information is a JSON document and get inserted into the Elasticsearch index, as well as additional JSON documents derived from its columns and spatial coverage that are put in other Elasticsearch indexes and used when searcing for possible joins.